
Why I Built This
I wanted a portfolio that doubles as a blog. Most templates force you to pick one or the other. I needed both — project showcases for employers, blog posts for learning in public.
So I built one from scratch.
Stack
Next.js 15 with the App Router. Tailwind v4 for styling. Contentlayer for type-safe MDX. Framer Motion for animations. Deployed on Vercel.
Problems I Solved
MDX Images Don't Play Nice with Next.js
Next's Image component needs width, height, and blur placeholders. Markdown images give you none of that.
I built a custom Rehype plugin that intercepts every image during build, runs it through Sharp, extracts dimensions, generates blur data, and rewrites the markup. Zero runtime cost.
Blog Series Need Navigation
Readers want "previous" and "next" links. They want to know where they are in a series.
I created a nested Contentlayer type for series metadata and a helper that computes navigation state from the content graph. Series order is explicit in frontmatter — no magic sorting.
Content Scattered Across Components
Fetching posts isn't complex. Doing it consistently across 10 different pages is.
I centralized everything in a content-service.ts module. One API surface. Environment-aware (shows drafts in dev). Handles filtering, sorting, and series relationships.
Results
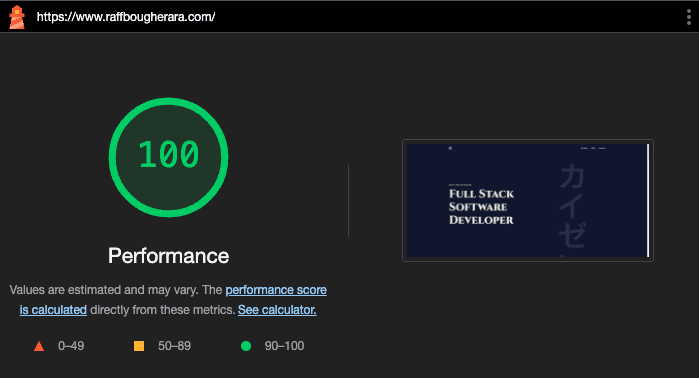
- Lighthouse: 95+ performance, 100 SEO
- LCP: under 1.5s
- CLS: near zero
The site ships fast because I treated performance as a constraint, not an afterthought.
What I'd Do Differently
Start with accessibility testing from day one. I added it late and had to retrofit some components.